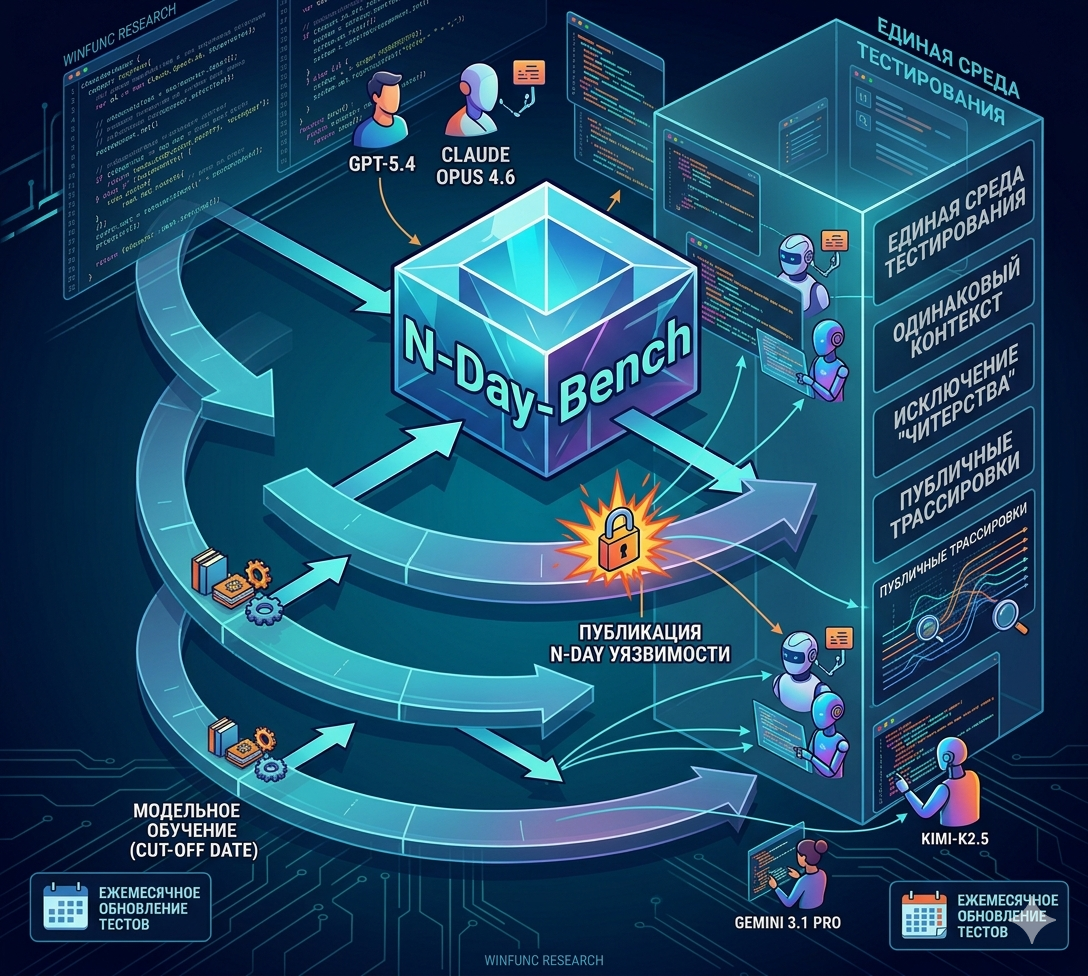
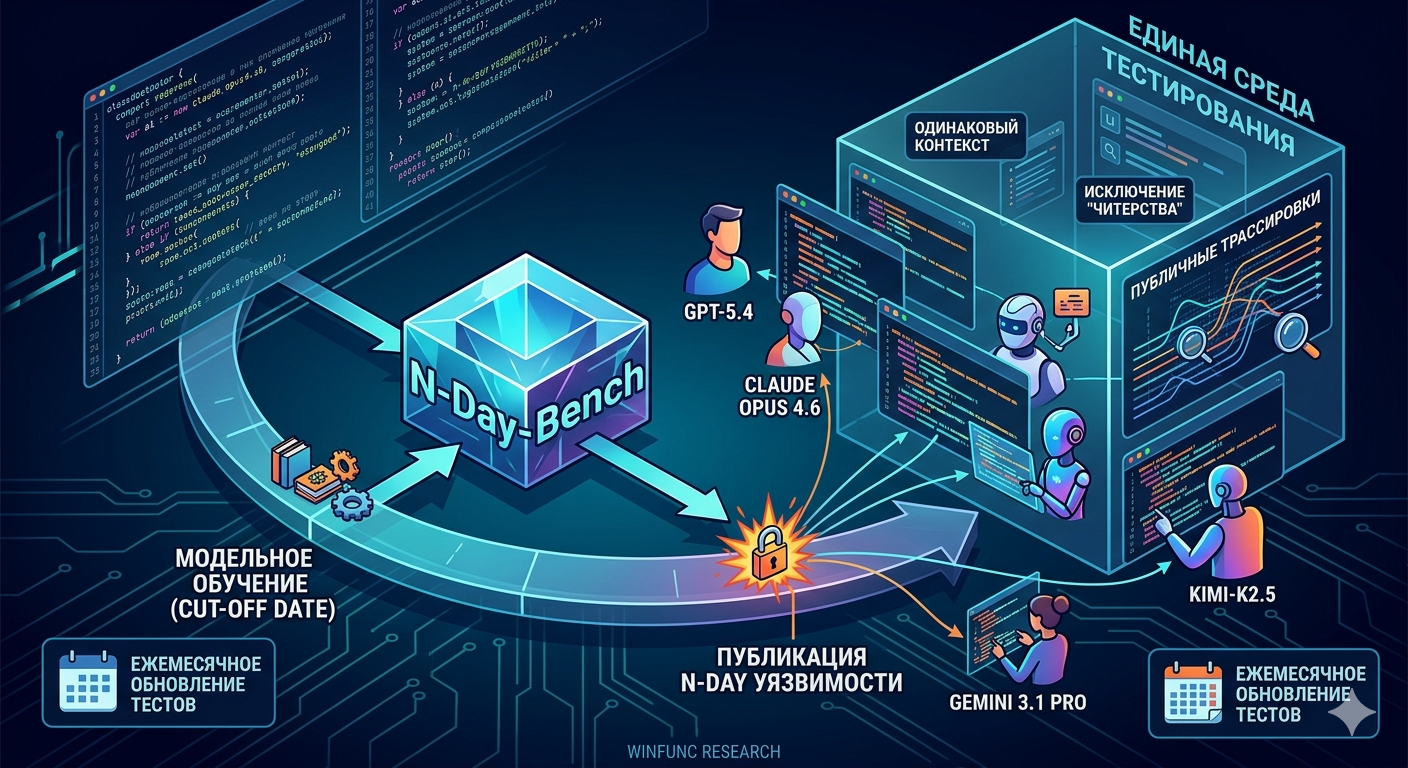
Исследовательская группа Winfunc Research представила бенчмарк N-Day-Bench — инструмент для измерения реальных возможностей больших языковых моделей (LLM) в области кибербезопасности, а именно в обнаружении уязвимостей.
В отличие от синтетических тестов, N-Day-Bench проверяет способность моделей находить так называемые «N-Day» — реальные уязвимости, публично раскрытые уже после даты отсечения знаний конкретной модели. Это исключает возможность «читерства»: модель не могла видеть информацию об уязвимости в процессе обучения.
Всем участникам предоставляется единая среда тестирования и одинаковый контекст, что исключает манипуляции с результатами (reward hacking). Все трассировки выполнения публично доступны для изучения.
Бенчмарк является адаптивным: тестовые случаи обновляются ежемесячно, а модели тестируются в своих актуальных версиях и чекпоинтах.
В последнем запуске бенчмарка участвовали ведущие фронтирные модели: openai/gpt-5.4, z-ai/glm-5.1, anthropic/claude-opus-4.6, moonshotai/kimi-k2.5 и google/gemini-3.1-pro-preview. Полная таблица лидеров с детализацией по каждой модели доступна на сайте проекта вместе с публичными трассировками отдельных запусков.
Источник: https://ndaybench.winfunc.com